Robots.txt files tells visiting robots – such as Google’s crawler – what they should and should not crawl. Part of this should be a Sitemap directive:
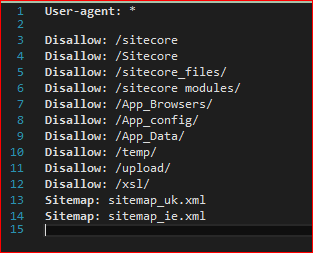
The Sitemap element(s) points to an XML file of all your pages of content, and when they were last updated. That way, the crawler can quickly and efficiently find new content.
Technically, the URL to the sitemap(s) must be absolute. Yes, there’s no earthly reason why this must be so, but that’s what the specification says. Fortunately, Google will handle relative URLs – so the definition shown above should work for Google – but it might not work for other robots. Continue reading “Don’t forget that Robots.txt Sitemap entries need to be absolute”

