It’s something that always mystifies me, it does seem that a lot of developers don’t know regular expression syntax very well. This came up when I was on some SharePoint 2013 training just before Christmas.
SharePoint 2013 introduces something called “Routing Rules”. These are rules that allow you to direct traffic to different front-end servers (or pools of servers), allowing you to isolate traffic, route to better health servers, etc.. Spence Harbar has a very good article about it.
Anyway, one some of the criteria that you can match rules on are Regular Expressions. However, SharePoint does warn you that Regex routing rules are slower – this is unsurprising. But how much slower than, say, a ‘Starts with’ or ‘Ends with’ rule? And on the Ignite training I did wonder about the efficiency of their example…
To test this I made some assumptions. First, I’m guessing that the record routing rules are written in C#, secondly, that the use the normal C# regex engine. Thirdly, I’ll assume that the ‘Ends With’ and ‘Starts with’ rules use the ordinary String class methods. If so, this would mean I could test the relative speed of the different rules, and perhaps whether the example from the training was a particularly efficient one.
I wrote a little console app, and contrived a test string of:
string target = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxMicrosoft One Note 2010";
I chose this because I wanted to try the Ignite example regex, which should match faster if the target string is at the end of the input:
Regex igniteRegex = new Regex(".*Microsoft One Note 2010*");
Regexper nicely resolves this to:

Cool. Now, the way regex engines match statements like .* is that, as they build up a stack of matching characters, this would make them capture the whole string to the end, and then they’d pop each character off the stack until it can match the next part of the regex.
My belief was that a simpler regex, such as:
Regex igniteRegex = new Regex("Microsoft One Note 2010");
Would be faster. This wouldn’t need to ‘scan backwards’ over the string. It’s also, notably, much less obviously a Regex – there’s no character classes, or operators to match multiple characters, etc.. Effectively, we’re just looking for that text within the string.
And, finally, I’d test an ‘Ends With’ using the String.EndsWith() method.
I’d try matches with each of these on the target string 1,000,000 times, to take a decent amount of time. So, the results?

Yup, that’s right – changing the regex save about 60% of the time, and using EndsWith() was 30% faster than that, too.
I’ve no doubt that the regex used in the training was just an example, but what concerned me a little was that, as I said at the start, I’m frequently surprised by how unfamiliar some developers are with regexes, and I’m not sure it was made clear enough the impact of the regex pattern. I mean, I wouldn’t have thought such small changes would make such a large difference.
Now, obviously this test is still a bit contrived. If I was putting this into production I think I’d be tempted to try to get a sample of the URLs I’d wanted to process – both items I wanted to match and not match – and then, similarly to above, I’d write a little console application to check my regex against them. I mean, the savings we’re talking about are tiny, but are for each request, and are comparatively easy.
Conclusion – design your regexes with care if using Routing Rules in SharePoint.
Additional: Charlie (see below) asks a good question – how does “Ends With” compare with a regex that matches ‘End String’ (i.e. $ ). My gut feel was that this would still be slower than without, but barely. The reasoning behind this was that the regex would still scan forward over the whole string until it found a match. EndsWith() is probably optimised for simply checking the tail. The most likely thing to upset this logic is if the Regex engine has an optimisation to realise that ‘something$‘ is equivalent to EndsWith(“something”) and so does that instead. My results?
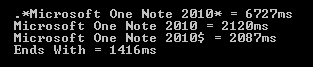 So you can see that the ‘End String’ character doesn’t make much difference in speed – less than 5% – which suggests that that string is still scanned forward.
So you can see that the ‘End String’ character doesn’t make much difference in speed – less than 5% – which suggests that that string is still scanned forward.

The dark art that is regular expressions! I’ve learned and forgotten the syntax many times over – these days I’ve resorted to keeping O’Reilly’s Regular Expressions handbook on my desk.
Out of interest what happens if you add an end of string marker to the regex (ie. new Regex(@”Microsoft One Note 2010$”) – is there still a performance gain when using string.endswith()?
Hi Charlie! Long time! Okay, that was a good question, so I’ve updated the above. Short answer – EndsWith is still 30% quicker. And yes, I have the O’Reilly Regular Expression book by Jeffery Friedl too; it’s my bible. I like that it actually explains how the underlying engines work, rather than simply telling you the syntax.